An Interview with Outlier Ash
I’m very happy to report that the Outlier Dictionary of Chinese Characters I wrote about before has met its $75k funding goal. That means that this dictionary will soon be available through Pleco, so if you were holding out, doubtful it would actually happen, doubt no longer. Congratulations to the Outlier Linguistic Solutions team!

Ash Henson
This is an interview with Ash Henson, Outlier Linguistic Solutions’ main academic guy. Like some other people I’ve spoken with, I was a bit apprehensive about the project at first, feeling it was all way too academic and probably not a good resource for beginners. The more I talked with Ash, though, the more I was convinced this was not the case. I do believe this is going to be a great resource for learners at all levels, and I look forward to using it myself, both for my own purposes, and for my beginner-level clients.
Anyway, here are some additional questions I had about the dictionary, answered by Ash.
1. You have an article on the problem with the concept of “radicals.” Would it be fair to say that radicals are just an outdated concept which we don’t need anymore because we can look almost everything up by computer now? Is your dictionary going to include the concept of radicals at all?
Well, I’d say that radicals are only reliable as a tool to look up characters in traditional dictionaries. If you only use electronic or software dictionaries, then it’s safe to say that you can ignore them. We will actually point out the radical for each character though, so that you can look up the radical for that character if you need to look it up in a paper dictionary. The main issue with “radicals” is that there are really several unique concepts that are called “radicals”. For instance, you often hear people say “Characters are made of radicals.” While that is a reasonable conclusion to make from the name “radical”, it misrepresents how characters actually work. There are around 500 semantic components that appear in characters and a lot of them cannot be broken down into “radicals”.
2. You’ve mentioned before that the Outlier Character Dictionary will include the most up-to-date research, including even corrections of mistakes in the legendary 说文解字 (Shuowen Jiezi). Could you give a simple example or two of that?
This type of data can be found in the Expert Edition. I’ll share two examples from the demo. For 監 (jiān) “to inspect”, the 說文 says that it is composed of the semantic component 臥 (wò) “to rest” which is used to express the idea “to look down from above” and the sound component 䘓 (kàn) “thick animal blood” abridged to 血. The problem is, 監 is a character from the early Shang dynasty (roughly 1600 bce to 1046 bce), while 臥 and 䘓 don’t appear until Warring States (roughly 475 bce to 221 bce).
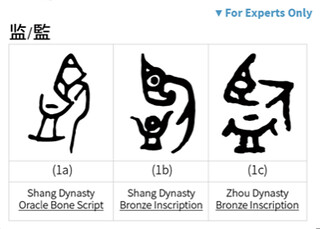
Image taken from the Outlier Dictionary of Chinese Characters
Obviously, either this interpretation is anachronistic or maybe 臥 and 䘓 did exist earlier and we just haven’t found any proof. However, if you look at the earliest extant forms of 監, it’s very obvious that it’s a picture of a person looking into a container that has liquid in it. This “picture” is used to represent the idea “to inspect, examine” as this was how the ancients inspected their own faces, i.e., they used water in a container as a mirror.
Another example is 黑 hēi “black”. The 說文 says that the top part is a window and the bottom part is flame (炎 yán) and gives the meaning of 黑 as “the color of something burnt”. Note that the 說文 is explaining the Small Seal script form. The earliest forms show a person with a tattooed face. This is one of the ancient Five Punishments, where the name of the crime a person committed was tattooed onto their face.
3. After all this time, how can researchers be certain about what are mistakes in the 说文解字 (Shuowen Jiezi)?
Basically by way of tracing characters back to their earliest extant forms and seeing how characters are used in earlier scripts. Like in the 監 (jiān) example above, the 說文 says that it’s composed of 卧 and an abbreviated 䘓, but 卧 and 䘓 show up around a thousand years after 監. It’s like explaining the 1066 war in terms of the soldiers’ cell phones. Keep in mind, the author of the 說文 was a very erudite scholar, with a very broad range of knowledge, but he was limited by the information he had access to and by pre-scientific thinking. The 說文 is best understood as an insight into how Han dynasty Confucian scholars looked at the Small Seal script. Even with its problems, it still plays a very important role in this type of research.
4. You’ve told me before that a proper understanding of characters can help a learner guess the correct pronunciation of a character. This is hard to imagine, since a lot of components have a wide range of possible functions and even multiple possible pronunciations. (Examples: 干、赶、汗、旱 or 今、含、零、领、邻) How can you solve this mess?
Sound components can be really frustrating, because they generally don’t give an exact sound. In the same way semantic components give a hint as to the range of meaning a character might have, sound components generally also just give a range of sounds. English speakers might not realize this, but English spelling is very similar. That’s why the exact same spelling “minute” can be pronounced MIN-it for “60 seconds” or mahy-NOOT for “extremely small”. Actually, this second one can also be pronounced mahy-NYOOT, mi-NOOT or mi-NYOOT. As you can see, the spelling “minute” does not give an exact pronunciation, but a range of possible pronunciations.
As a native-English speaker, this isn’t a huge problem, because for the most part, we go from words we already know how to say correctly, to learning how to write them. During college we learn a lot of new, specialized words for the field of work we are training for. Most of these are learned either from reading or from hearing professors or other students use them. When I was in college, I often heard people say words incorrectly because they had only seen them in writing. This is a reflection of the fact that English spelling only gives a range of possible pronunciation rather than an exact, IPA-like pronunciation.
Making sense of sound patterns in Chinese characters is very useful, because they can be used to remember how to write characters. For instance, before I learned how sound works, whenever I had to write a character containing 艮 or 良, I would always ask myself, “Oh, man. Do I put that dot here or not?” It was very frustrating. Once I learned how sound components work, I looked up the pronunciation for 艮 (gèn) and 良 (liáng). Then I noticed that for characters pronounced “gen”, “hen”, or “ken”, it was 艮. If it was pronounced “lang”, “liang”, “nang” or “niang”, then it was 良. So, by learning about sound relations, I went from a meaningless dot-or-no-dot question, to a meaningful “What is the pronunciation of the character I want to write?” question. Though sound isn’t represented exactly in Chinese writing, there are a lot of clues we can use, especially if we know to look for them.
Now to the examples you brought up: 干、赶、汗、旱 or 今、含、零、领、邻
Let’s look at 干 (gān), 赶 (gǎn), 汗 (hàn), and 旱 (hàn) first. Notice that they all have the ending “-an” and that they all share the component 干. This is a strong clue that there is a sound relation. Also note that there is no discernible pattern with the tones. That’s because tones generally are not taken into account. Native speakers would generally use “-an” as the sound clue. However, it’s very useful to remember that “g-“, “k-” and “h-” are very closely related sounds.
As for 零 (líng), 领 (lǐng), and 邻 (lín). Notice that 令 is pronounced “lìng.” Once again, tones don’t count (not to say they aren’t important! They just aren’t represented by the sound component). Lastly, notice that the sound for 邻 ends in “-n” and not in “-ng.” In this particular case, that’s due to the simplification of 鄰 to 邻, and 粦 is pronounced “lín.”
Finally, looking at 今 (jīn) and 含 (hán), we notice that 今 and 令 above are graphically very similar, but like the 艮 (gèn) and 良 (liáng) example, we can use sound to keep 今 (jīn) and 令 (lìng) separate. Using sound patterns to understand the relation between 今 (jīn) and 含 (hán) is a little more complex. You have to understand both that “g-“, “k-” and “h-” are closely related as previously mentioned and that many “j-“, “q-“, and “x-” come from an earlier “g-“, “k-” and “h-“. In other words, two groups of closely related sounds are also somewhat related.
Why do sound series have this kind of variation? The answer to this question is fascinating, but complex. Most characters in use today find their origins thousands of years ago during the Zhou dynasty. Back then, the language was very different and very possibly had prefixes and suffixes and it was these prefixes and suffixes which cause this variation. Another reason is from regular sound changes over the last several thousand years.
5. Your dictionary is designed to provide a wealth of modern character research into characters through a modern interface. How would this be used by a beginner who sees characters as an annoying hurdle?
The key to optimal learning is obtaining the ability to use the system of Chinese characters as a tool for being able to recall character forms after long periods of time and as a tool for making intelligent guesses about characters you haven’t learned yet. Native speakers have these abilities, but they are far from perfect and they are the results of years of input. Non-native speakers learning Chinese can also get them after learning a few thousand characters.
However, as you can imagine, their instincts about characters are probably not as good as a native speaker’s. The main advantage of using our methods is that you can gain these abilities after a few hundred characters, because all of the sound and meaning connections are being pointed out explicitly for each character. And, as I showed above, if you learn our sound patterns, your feel for sound representation will be better than a native speaker’s. We also explain meaning connections in a more precise way, so your feeling for meaning representation will also be more accurate.
To those who think of characters as a nuisance, if you learn them our way, you’ll learn in a way that is both more meaningful (and therefore you’ll likely find it more interesting) and more effective, so you’ll spend less time re-learning characters. We can’t remove the pain entirely, but we can minimize it!
As of today, the Outlier Dictionary of Chinese Characters Kickstarter is sill going.
There’s a small typo in “Also note that there is not discernible pattern with the tones.”
It’s great to see this happen! I can’t wait to download this dictionary to my phone.
Ah yes, thanks! Fixed.
Very excited for the dictionary plugin. Wish I had had it when I started learning characters.
I just read, that you (John) (and Olle) will be responsible for creating a workbook. Will it include a beginner’s guide that will enable a complete hanzi-noob to learn the first 100+x or so hanzi taking advantage of the dictionary?
Björn,
Yes, that’s the idea, although I can’t officially commit to anything because we’re still working out the details.
It’s interesting to note that some of the apparent sound inconsistencies in Mandarin don’t exist in dialects. For example, 鹅,饿 and 我, although pronounced as ‘e’ and ‘wo’ in Mandarin, are all pronounced as ‘ngo’ in Cantonese. This is probably an indication that often characters which are now pronounced differently were pronounced differently in older forms of Chinese.